I Built a Music Audio Features API Because Spotify Killed Theirs
In November 2024, Spotify deprecated their Audio Features and Audio Analysis endpoints. No replacement, no migration path. A lot of music apps quietly broke. DJ tools, playlist generators, recommendation engines, game audio systems. If your app needed BPM, key, energy, or danceability for tracks, you were out of luck.
I needed those features for a project. Nobody had built a replacement. So I built one.
MeloData is a music audio features API. You give it an ISRC (the International Standard Recording Code, the universal identifier that every commercially released track has), it gives you BPM, key, energy, danceability, and more. If the track has been analyzed before, you get results instantly. If not, it analyzes it on demand and caches it permanently.
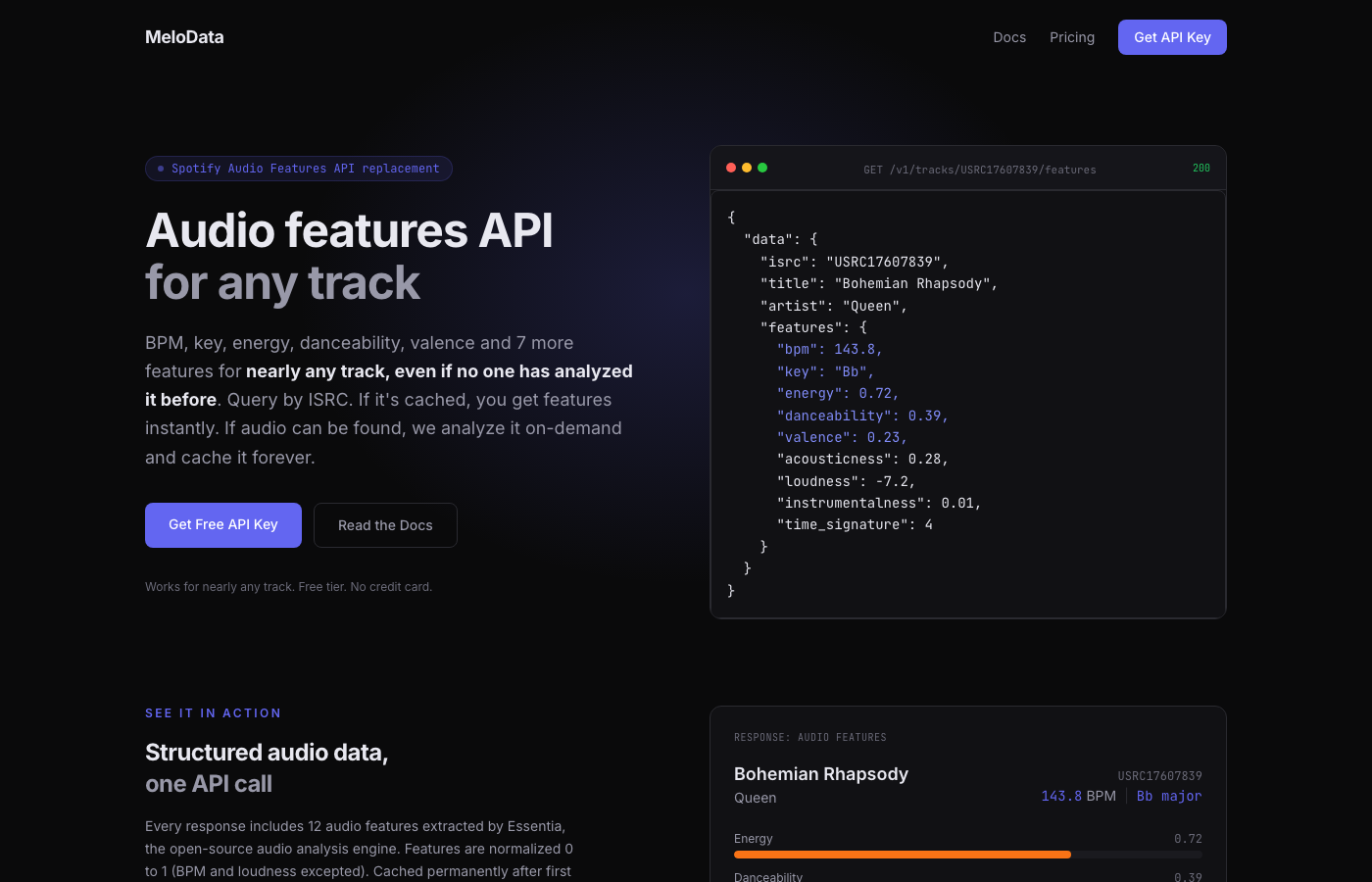
The 202 Pattern
The interesting technical decision was how to handle tracks that haven't been analyzed yet. Spotify had pre-computed everything. I couldn't do that for every song ever released.
The solution: return HTTP 202 (Accepted) for cache misses.
GET /api/v1/tracks/USUM71507009/features
If the track is cached, you get a normal 200 with features:
{
"data": {
"isrc": "USUM71507009",
"title": "Run Away With Me",
"artist": "Carly Rae Jepsen",
"features": {
"bpm": 119,
"key": "C#",
"energy": 0.72,
"danceability": 1.0,
"speechiness": 0.307,
"time_signature": 4
}
}
}
If it hasn't been analyzed, you get a 202 with a Retry-After header:
{
"data": {
"isrc": "GBDUW0000059",
"status": "analyzing",
"estimated_seconds": 30
}
}
The client waits 30 seconds and retries. By then, the track is analyzed, cached, and every future request gets instant results. The 202 is not billed, so you only pay for actual feature lookups. For higher volume or latency-sensitive applications, webhook support is available to avoid polling.
This means the database grows with usage. Every user who queries a new track makes the API better for everyone.
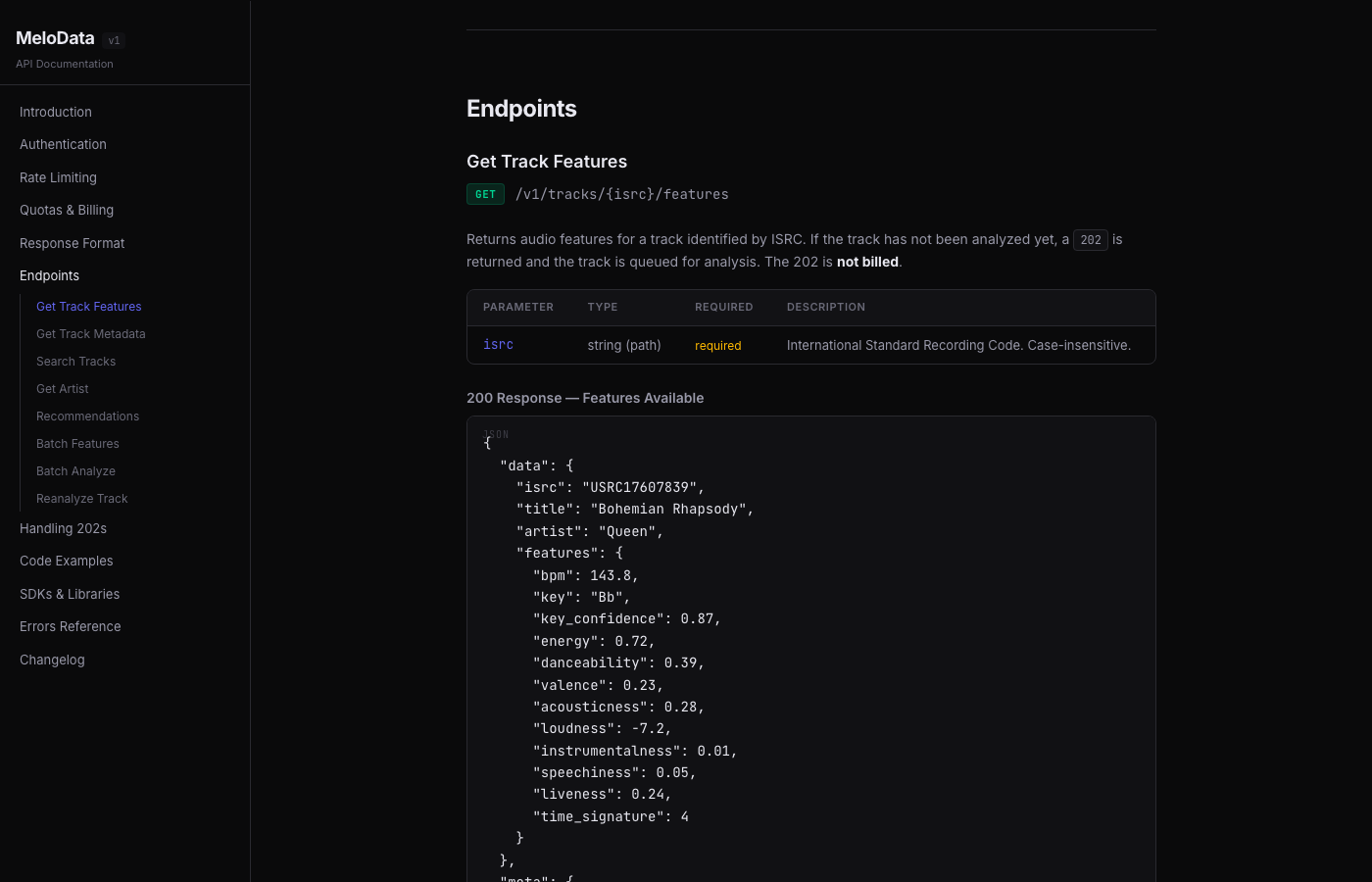
How the Analysis Works
The analysis worker uses Essentia, an open-source audio analysis library from the Music Technology Group at Universitat Pompeu Fabra in Barcelona. It's the same library used in academic music information retrieval research.
For BPM, the worker runs three algorithms and picks the most confident result:
- RhythmExtractor2013 with two different methods (multifeature and degara)
- PercivalBpmEstimator as a third opinion
The worker takes the median, weighted by confidence scores. It also cross-references against catalog BPM data from Deezer when available and applies octave correction (a common BPM detection error where the algorithm reports half or double the actual tempo).
For key detection, it runs Essentia's KeyExtractor with three different tonal profiles (EDMA, Krumhansl, Temperley) and picks the result with the highest confidence.
Energy comes from DynamicComplexity, speechiness from spectral analysis of the 300-3400 Hz vocal band, and danceability from Essentia's built-in algorithm.
How Audio Sourcing Works
A common question: where does the audio come from?
MeloData uses publicly available 30-second audio previews that streaming services provide for discovery purposes (the same clips you hear when you hover over a track in a music store). No full tracks are downloaded or stored. The worker downloads a preview, runs analysis in memory, extracts numeric features, and deletes the audio file. Only the derived metadata (BPM, key, energy, etc.) is stored.
This is similar to how services like Shazam or AcousticBrainz work. The audio is transient. What persists is math.
The tradeoff is coverage. Spotify had access to their entire catalog. MeloData depends on previews being available, and not every track has one. Some region-locked or independent releases come back as "unavailable." The database starts with 51K pre-analyzed tracks from AcousticBrainz and grows as users query new ISRCs.
The Stack
The API is a Next.js app deployed on Vercel. The analysis worker is a Python service running on Railway in a Docker container with Essentia and FFmpeg installed.
They communicate through internal API endpoints. The worker polls for jobs, claims them atomically (PostgreSQL function to prevent double-processing), downloads a 30-second audio preview, runs the analysis, and posts the results back.
The database is PostgreSQL on Supabase with about 51,000 tracks pre-seeded from AcousticBrainz archives. Redis on Upstash handles rate limiting, API key caching, and quota tracking.
Authentication is Bearer token based. API keys are SHA-256 hashed before storage. Rate limits and quotas are enforced per-key with sliding window counters in Redis.
What I Learned
AcousticBrainz was a goldmine. The now-defunct AcousticBrainz project archived millions of crowd-sourced audio analyses. I seeded the database with 51K tracks from their dumps, mapped to ISRCs via MusicBrainz. This means many popular tracks already have features without needing on-demand analysis.
Audio preview availability is the bottleneck. The worker finds audio through Deezer previews (free 30-second clips). Some tracks, especially from smaller labels or region-locked releases, don't have previews available. Those come back as "unavailable." Spotify didn't have this problem because they had the full catalog.
The 202 pattern is surprisingly clean. Clients that handle it are resilient, and the retry cost is near zero. It turns a cold-start problem into a one-time 30-second wait per track that never happens again.
Limitations
Being honest about what this is and is not.
Accuracy. BPM detection is solid for most genres. The multi-algorithm consensus approach catches most octave errors. Key detection is good but not perfect, especially for songs with key changes or ambiguous tonality. Every response includes a confidence score so you can decide what to trust.
Coverage. This is not a Spotify replacement in terms of catalog size. Spotify had 100% of their library pre-analyzed. MeloData has 51K seeded tracks and grows on demand, limited by audio preview availability. Some tracks will come back as unavailable.
30-second previews. Analyzing a 30-second clip is not the same as analyzing a full track. For most songs, 30 seconds is enough to get reliable BPM, key, and energy. For tracks with long intros or dramatic changes, the preview window matters.
ISRC requirement. You need the ISRC to query a track. Most music databases and streaming APIs expose ISRCs, but if you only have a song title and artist, you need to resolve the ISRC first. A search endpoint is available for tracks already in the database.
Try It
The free tier is 1,000 lookups per month, no credit card. The first 50 users get an extra 500 lookups as an early adopter bonus.
The API is live. If you find a bug or have feedback, reach out at support@voltenworks.com.